以下仅为演讲大纲,具体录像请点击
纯 RL 在复旦貌似没什么资源,也没有老师做这个方向的,但是却做出了人工智能最早出圈的成果之一(击败了柯洁的 AlphaGo),Google 的 Deepmind 团队在 AlphaGo 之后在星际争霸 2 继续了他们的 RL 研究。在 2019 年,Deepmind 发布 AlphaStar,登顶 Nature 期刊封面,并且在暴雪嘉年华也击败了星际争霸 2 最强的职业选手 Serral
而 Deepmind 的工作远不止最出圈的 AlphaStar,对于星际争霸 2 的 RL 研究更重要的基石其实要追溯到 2017 年,Deepmind 发布了 StarCraft II: A New Challenge for Reinforcement Learning(http://arxiv.org/abs/1708.04782),而这无论是对学术界还是对工业界而言,都是影响巨大、毫无疑问的开山之作
尽管是快 8 年前的工作,但是 paper 的含金量毋庸置疑,且至今都在学术界与业界影响巨大。最近一直在学习这方面的内容,理解仍然非常浅薄,但是刚好有个机会让我去分享这方面的工作,尽管时间比较紧,其实看的不是特别透彻就得讲了…但实在心痒难挠,也只好冒着撞墙撞得鼻青脸肿的风险来跳梁献丑、贻笑方家了。列位只当是一家之辞,笑话之余还望海涵
Introduction
众所周知,在 2016 年时,由 Google Deepmind 发布的 AlphaGo 击败了世界冠军李世石,之后又击败了积分榜第一的柯洁,成为了当时的热点话题。
在 2017 年,Deepmind 的 RL 工作从围棋转型至星际争霸 2,同年携手暴雪发布了 SC2LE
StarCraft II: A New Challenge for Reinforcement Learning
在 2019 年,Deepmind 发布 AlphaStar,登顶 Nature 期刊封面

为什么要用游戏做 RL?
- 游戏有明确的成功量度指标(输了或者赢了),以便模型给予 reward
- 有量度玩家实力水平的 天梯分数/排位段位
- 游戏所在的虚拟环境,对于深度网络来说,是一个很好的输入;在现实世界中可能会有很多噪音情况,导致并不是最合适的输入数据
- 游戏本身是一个很好的挑战,也是一个很多人类的需求。因此研究有意义
- 并且 Benchmark 也可以参考 Deepmind 的工作,实验数据可以以某个段位作为一个 baseline,击败现在世界最强的职业选手那就是 SOTA 了
- 如果是做具身之类的 RL 的话,开发者是用不同环境去训练和 Deploy 的(比如说我在复旦大学,另外一个想要复现我工作的在香港大学),有很多客观上的条件也不一样。
- 但是大家跑的游戏都是同一款,在同一个服务器上,同一个环境下进行。
为什么用星际争霸 2 这个 domain 作为落地场景?

频繁去探索,改变状态,得到奖励
- 通过不断调整 local camera 来探索信息
- 通过探索战争迷雾去得到信息
- 每个单位都有自己的一些属性,这些状态会频繁被改变
如果用 MDP 表示的话(这个只是其中一个例子)
- S:观测到对方的单位
- A:操作自己的单位,进攻对方的单位
- R:击杀对方的单位 -
以星际 2 作为落地场景,可以遇到很多对于 RL 来说比较有意义的挑战(如上图所述):
- 巨大的状态空间、动作空间
- 作为一个 RTS 游戏(即时策略游戏),需要尽快地做出决策,延迟的决策会影响很多结果
- …
相对于其他的同类游戏,Google Deepmind 构建了 SC2LE(StarCraft II Learning Environment),专门为 RL 研究者直接能对游戏进行研究的环境,其他游戏的话没有前人的工作,需要自己手动搭建一套非常工程且耗费人力、资源的框架,基本是一个非大厂级别的研究机构完全无法承受的。
- https://github.com/Blizzard/s2client-proto
- https://github.com/deepmind/pysc2
- 通过 SC2LE,用代码控制游戏操作,环境还提供了暂停时间、开全图、改变游戏速度等等的功能,能让研究者可以通过这些特殊的且正常游戏下无法实现(能实现是因为 Deepmind 和暴雪合作了)的功能来实现一些 special purpose

Google Deepmind 的工作
StarCraft II: A New Challenge for Reinforcement Learning
Deepmind 发布的专门用于 RL 的训练场景

Mini Games,这篇 paper 提供了一些游戏大厅地图,专门用来训练 Agent 一些很简单的操作,一些基础的运营,一些基础的微操。
- 比如第一个,每当枪兵到达一个灯塔,就给予奖励,训练 Agent 基础的控制兵种能力
给想要做 SC2 RL 的研究者提供了 Benchmark
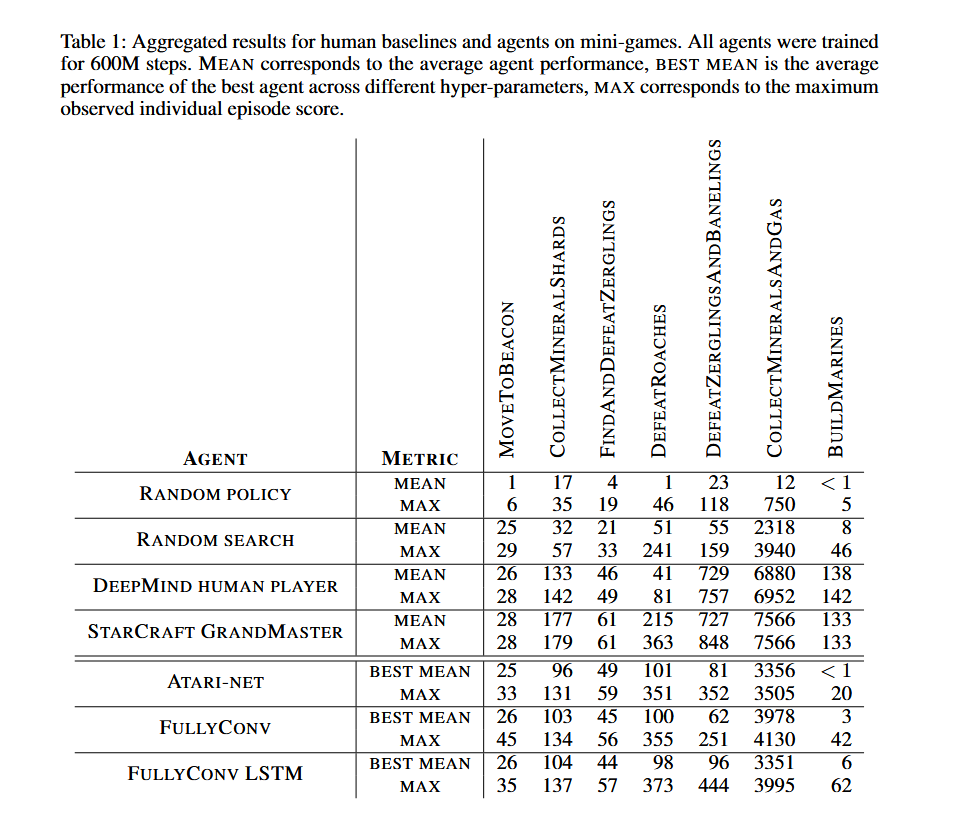
- random policy 是从整个 action space 里面去选的
- random search 是 based on FullyConv agent 的
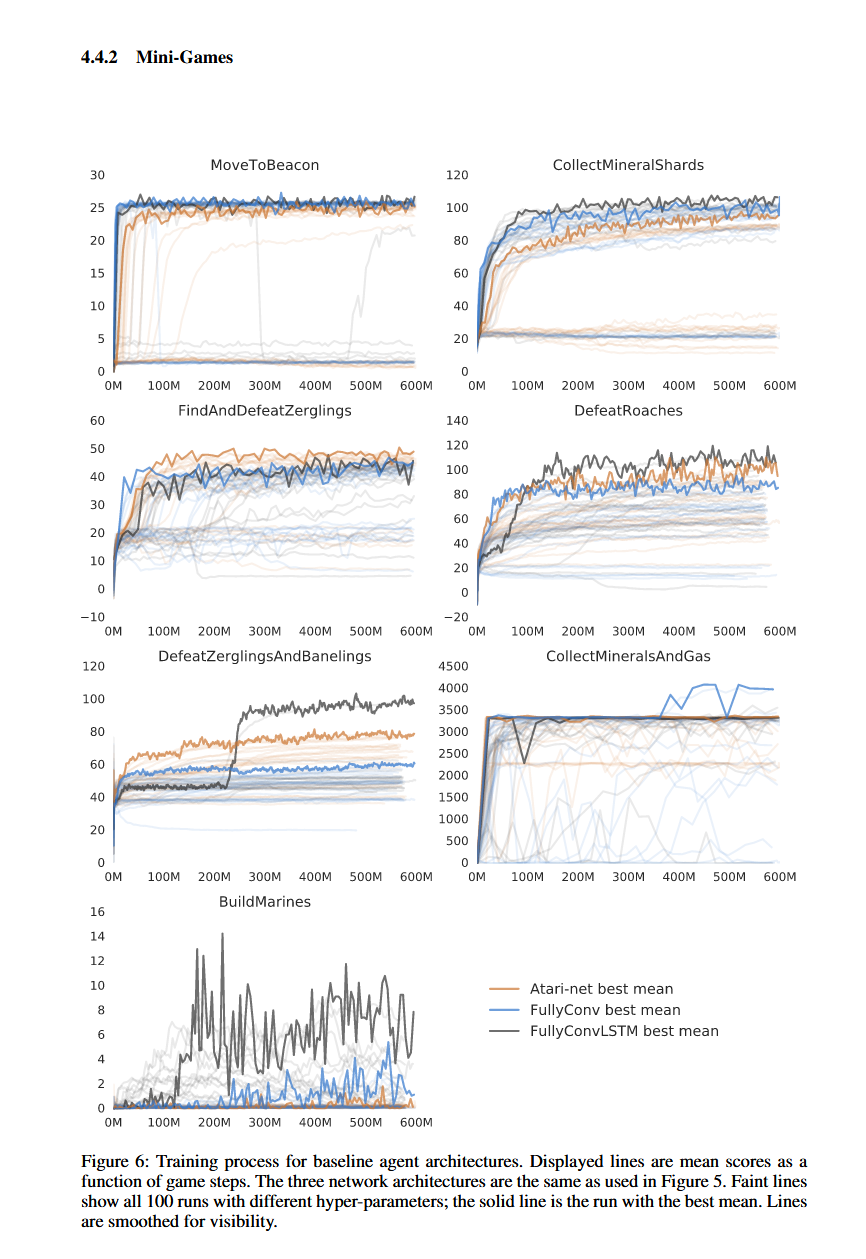
承上,是 minigame 场景下的 baseline
RL 学习算法

- 主要是介绍了策略梯度算法
- 定义了策略 πₐ。在每个时间步,Agent 接收观察 sₜ,并选择一个行动 aₜ
- 参数通过 A3C 优化
- Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy P Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. ICML, 2016.
训练方式
- minimap
- 完整游戏:和游戏内置 AI 打
- 游戏内置 AI 的策略都是编程写好的,包括怎么发展,在几分钟进攻等等
ORM 模型
- 输(以及平局)=0
- 赢=1
PRM 模型
- 游戏结束后,会有一个根据游戏中的单位总量、资源收集、消灭单位、消灭建筑等等指标的一个“游戏得分”,通常只能在游戏结算画面看,Deepmind 通过和暴雪合作,让游戏能即时获取这个分数,即时对行为进行奖励
- 不过,已经有研究表明星际内部的游戏得分并不会对星际 AI 的训练有所帮助。
- 而 wtl 等赛事的衡量大部分是人类主观的打分,难以通过大数据计算;至于 elo 分数等方法则和胜率一样,很难关注到星际 AI 的各个方面。
使用到的神经网络架构
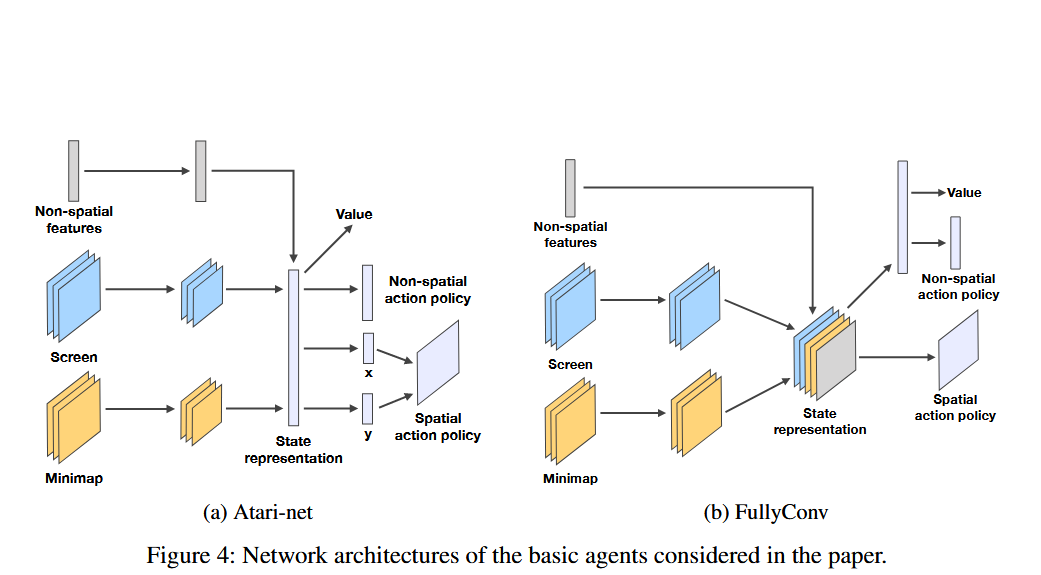
Atari-net
- 类似于为 Atari 游戏设计的 Network architecture
- 传统的 DQN 架构;先扁平化到 state representation;到输出之间还有一个中间层/连接层
FullyConv
- 所有层都是卷积层,没有全连接层。
- 使用卷积网络来保留屏幕和小地图动作的空间信息,更考虑空间信息
使用上述训练策略,在完整游戏上的结果
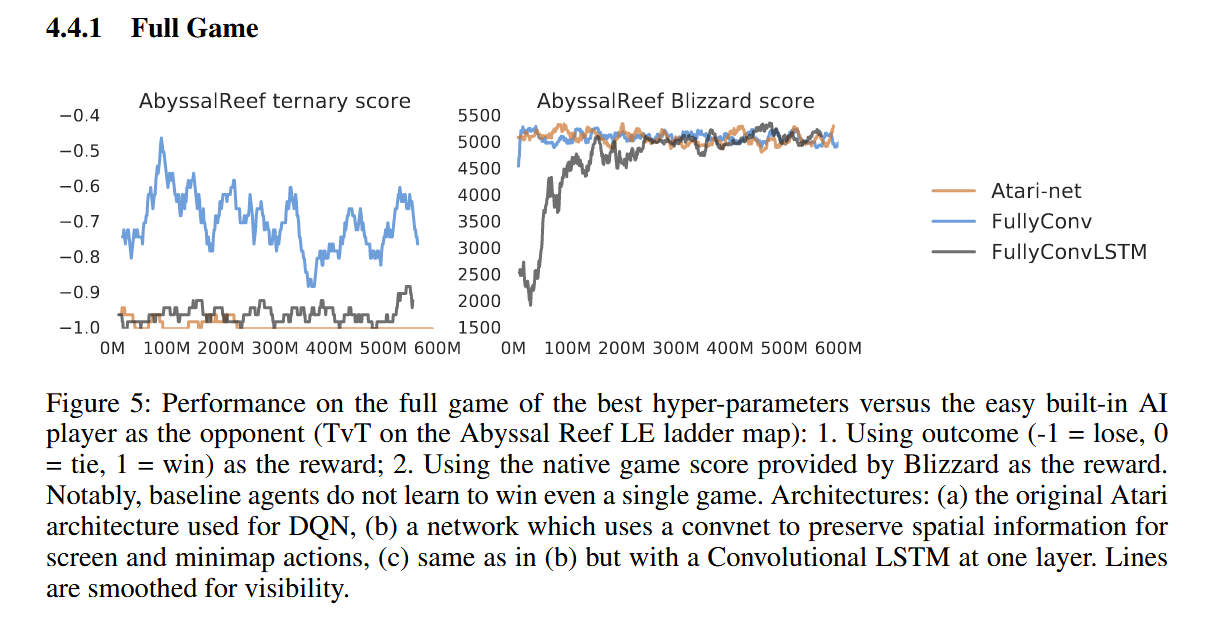
- 整体对游戏内置简单 ai 的表现都非常差,加了 LSTM 的效果比消融版更差,GRU 可能是更好的解决方案
- FullyConv 通过人族建筑升起达成平局,表现比其他两个好一点
还会用到有监督训练,用到了 dual-headed networks
会在以下两个结果导向/过程导向的损失函数去做权衡与计算,从而做出 Action
Value Predictions (predict outcome)
- 预测游戏的输赢(没有平局)
- 相对而言是比较难去做预测的,因为游戏胜负的预测本来就难料,而且是稀疏奖励场景
- 根据一个 Single Frame 来 predict output(比如根据战局现场预测,但是这没有考虑到很多信息,比如对手隐藏了的部队等等)
Policy Predictions
- 预测某个时间下,玩家进行的行为
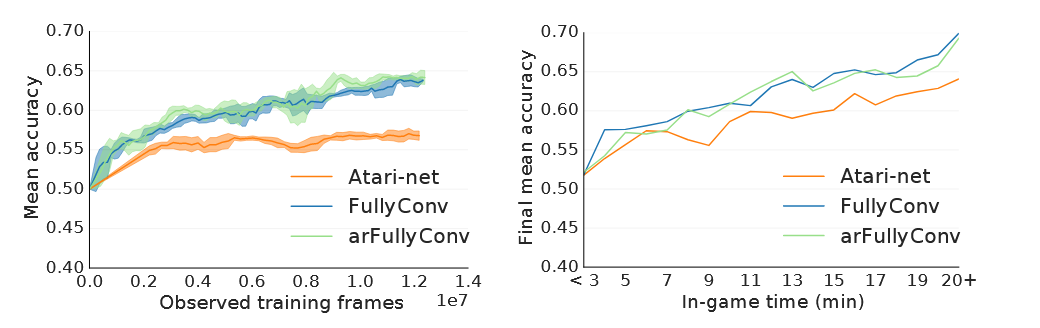
arFullyConv:加了 auto-regressive,理论更好,但效果和 FullyConv 相当
一开始是 50%左右,因为游戏开始时基本是随机的、难以预测,且稀疏奖励,后面预测的效果都不错
训练方式
- 通过学习游戏录像训练 - 模仿学习,根据一些专家数据来学习策略
Related Work
下面这两篇是 Weiyu Ma(Meisah) 大佬的工作,我和这位大佬的交流也蛮多的,从中学习到不少知识,马院士的这两篇工作很容易复现,也是这个领域比较近期的产出,虽然不是很 RL,但是也推荐大家一看:
LLM Plays SC2, 中了 NIPS,上了三顶会
https://mp.weixin.qq.com/s/5SQZxIY8y26TWfO35yfpiQ
http://arxiv.org/abs/2312.11865
- 模型的推理延迟是一个很大的问题,以后如果出现一些能力密度比较高的小模型可能会比较好
VLM Plays SC2
http://arxiv.org/abs/2503.05383
AlphaStar
https://www.nature.com/articles/s41586-019-1724-z
- 监督学习+强化学习
- PFSP:prioritized fictitious self-play 带有优先级的虚拟自博弈
- 说白了就是给 ai 设计一个联赛,让 ai 不停的通过打比赛来变强
- 所有先进的神经网络全部上一遍:CNN,RNN,Transformer,MLP 全都有
- 大量的计算资源和训练数据:百万 rep+海量 TPU,权重参数千万级
一共 42 位作者参与的庞大工程,不愧是 nature 封面之作,但是可复现性极差,大家根本没有那么多计算设备和人力.这也带来了之后研究的问题,哪怕是复现 AlphaStar 的工作,都变得异常困难.
腾讯的星际 AI 三部曲
TStarBots,TStarBot-x 和最新发布的 ROA-Star.
出乎意料的是,腾讯在游戏强化学习界一直是打王者荣耀为主的,很少有人关注他们的星际 AI,不过最近看了一点文献之后发现他们还是有不少产出的.
第一篇 TStarBots,论文链接:[1809.07193] TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game (arxiv.org)
这篇文章在 AlphaStar 之前就完成了,使用了 SC2LE 环境,设计了虫族 ai 能够战胜作弊三电脑
第二篇工作 TStarBot-X,论文链接:[2011.13729] TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game (arxiv.org)
这篇工作紧随 AlphaStar 之后,也是第一部的改进版,这次虫族 ai 实力更加强劲,可以赢业余选手了.(小道消息,赢的是王哥的虫族)
三部曲的最后一部 ROA-Star,论文链接:pdf (openreview.net)
ROA-Star 彻底突破了之前工作的瓶颈,首先他不用虫族了,开始玩 p 了(这里就不黑 P 了,不过确实大家都喜欢做神族 ai,毕竟 DeepMind 开了个头).论文的实验部分也很有意思,和 SED,CYAN,JIESHI 打了 bo20,保持胜率在 50%,而且还和小 hero 打了 bo3.说明这个 ai 稳定性是真的强,也不怕对手针对.不愧是
A Robust and Opponent-Aware AI(ROA 就这么来的).这篇文章还中了 NeurIPS 2023 Spotlight
技术特点:
- AlphaStar 的框架打底
- 使用了对手建模网络
- 使用了一个目标条件下的利用者,简单来说就是让 AI 专门学小天才来狗你,让你学会如何不被狗币狗.
- 加了侦查的 reward
- 计算资源这边只用了 46 张 v100,看起来有落地的潜力了
南京大学星际 AI 三部曲
介绍完了腾讯的星际 AI 三部曲,来看看南京大学 liuruoze 博士的星际 ai 三部曲:TG,mini-Alphastar,HierNet-SC2.南京大学的俞扬老师是中国强化学习界的知名学者,liuruoze 博士也是他的门徒之一,靠着学校的资源就完成了三个星际争霸 2 AI 的开发,属于是 one man army 了.他的工作可复现性很强,计算资源消耗并不多,而且都开源了.(三篇都是神族 AI)
这篇工作主要是利用人类经验来构造一个 model-base 的 RL 学习方法
第二篇工作是 mini-AlphaStar,论文链接:[2104.06890] An Introduction of mini-AlphaStar (arxiv.org)
这篇工作主要是探究如何能够高效的筛选出学习的参数和动作空间.因为星际争霸 2 实在是太耗计算资源了,作为一般的学者而言根本弄不了这个.但是 mini-alphastar 就致力于解决这个问题
第三篇工作也是重头戏,长达 48 页的力作 HierNet-SC2.利用分层强化学习和数据挖掘技术,跳过监督学习,从 0 学习星际争霸 2.
论文链接:[2209.11553] On Efficient Reinforcement Learning for Full-length Game of StarCraft II (arxiv.org)
技术特点:
- 数据挖掘找到人类最常用的动作
- 分层强化学习:最终版使用了三层的分层强化学习,极大缩减了学习空间
- 只用 4 张 v100,这下基本上有几个钱就可以试着玩了.
- 细致的 reward 设计,解释了 spare reward 和 dense reward 对星际争霸 2 ai 的影响(dense 虽然好,但和最终性能没啥关系)
- 采用了和 alphastar 不一样的动作空间,保证了和人类的一致性(alphastar 实际上还是调接口,所以他的操作才那么变态)
SCC(启元)
- 人族 ai,以爆维京战机出名的启元流
DI-Star
虫族 ai
中国虫王 IA 在星际上的最后一舞.去年也是在 bilibili 上放出了演示视频和 github 的 demo,但是并没有论文放出来啊,还是说我没找到?
不过还是把 github 放出来:opendilab/DI-star: An artificial intelligence platform for the StarCraft II with large-scale distributed training and grand-master agents. (github.com)
直接可以部署在本地电脑玩的星际 ai,不知道他们的这个策略蒸馏怎么做的啊,或许这就是商汤的技术力吧(不过他们现在应该是上海 AI lab 了?)
DeepMind 的又一力作
AlphaStar Unplugged,离线强化学习也能玩星际!
论文地址:[2308.03526] AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning (arxiv.org)
离线强化学习一直以来实际上不太被游戏 AI 所关注,毕竟游戏 AI 可以直接 online 学.DeepMind 通过百万级的 replay 来进行离线强化学习(在数据集上学到最好的策略),最终是击败了之前 AlphaStar 中的 SL(监督学习)ai.
技术特点:
- MCTS 蒙特卡洛树搜索,没想到也能用在星际上,
- offline RL,实现了好多算法,也实现了 offline 的 Actor-Critic.
如果想要从事这方面的研究,我应该去哪里?
- 学术界:南大的俞扬老师,交大的俞勇老师
- 业界:比较推荐,像是腾讯这样的大厂里面也有做很多 RL,也有很多产出。因为学术界通常没资源(显卡资源、人力资源)不是很多,像是复旦就没什么做纯 RL 的老师。而且水平整体是比业界差一截的(不过业界通常把成果藏着掖着,只用在自己产品里面,免得被别人抄了。但是那种特别革命性的成果或者非常震撼的产品,又通常来自于业界)。简单举个例子,像是 AlphaStar 这样的工作,就非常需要 GPU 资源去复现,没卡就更别说是进一步的探索了。